How to Replace a Competitive Intelligence Analyst With AI
A competitive intelligence analyst in the US makes about $120,000 a year (Glassdoor, Feb 2026 — $92k at the 25th percentile, $159k at the 75th). Senior ones clear $150k.
Here’s what that money buys: someone who watches your competitors so you don’t have to. They track maybe fifteen rival products, notice when one drops a price or ships a feature or raises a round, figure out whether it actually matters, and tell the team before it shows up in a lost deal.
Strip the title away and the job is a loop:
watch → notice what changed → decide if it matters → write it down → tell someone.
Run that loop every day, forever, without missing a day. That’s the whole role.
Loops that run forever without missing a day are the one thing software has always been good at and humans have always been bad at. So we pointed an agent at it. It’s been running the competitive watch for this company for weeks. Here’s exactly how — and where it still needs a human.
Can AI replace a competitive intelligence analyst?
The honest answer: it replaces the surveillance, not the judgment — and surveillance is ~80% of the hours.
The part that eats an analyst’s week isn’t the brilliant strategic memo. It’s the grind: re-checking the same fifteen pricing pages, re-reading the same changelogs, re-running the same searches, 90% of which turn up nothing changed. That grind is pure loop, and an agent runs it for the cost of a few cents of compute a day instead of $120k a year.

What’s left — “is this move actually a threat, or noise dressed up as a threat?” — still wants a human in the loop. The trick is building the agent so a human only ever sees the 10% worth a human’s attention.
That’s the design. Let me show you the machine.
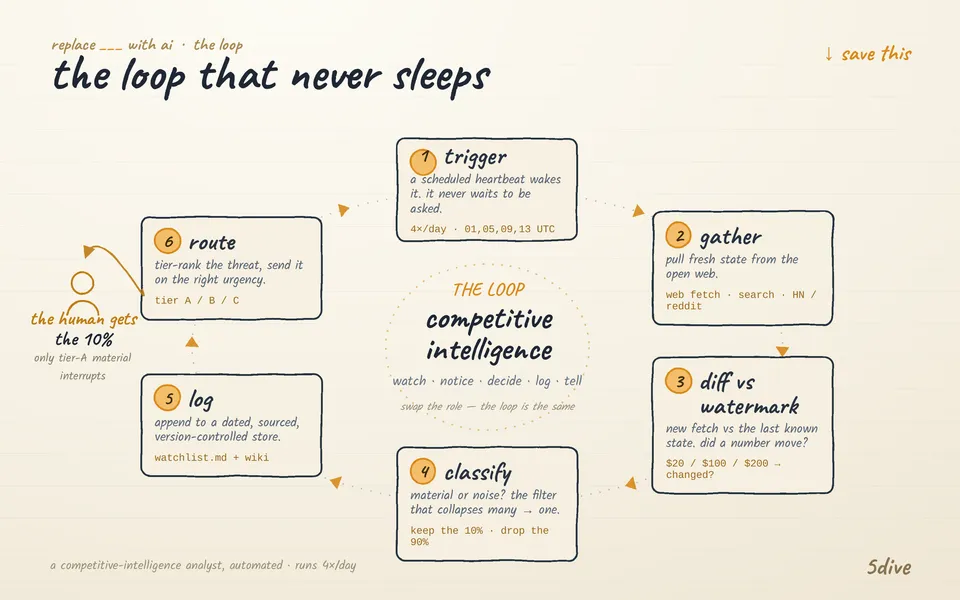
The loop, drawn out
A competitive-intelligence agent is just the analyst’s loop, made literal:
1. Trigger (perceive). It doesn’t wait to be asked. A scheduled heartbeat wakes it four times a day. Ours runs on a cron — 0 1,5,9,13 UTC — two full briefings (morning + evening) and two gated interrupts in between that only escalate if something broke.
2. Gather. On each wake it pulls fresh state from the open web: competitor homepages and pricing pages fetched directly, Hacker News via its search API, Reddit via the public JSON endpoint, funding and launch news via search. It doesn’t check all fifteen rivals shallowly every day — it cycles through competitor clusters on a fixed rotation, so each product gets a scheduled deep-scan when its turn comes up instead of a casual daily glance. The dynamism is in where it points its attention, not in re-asking the same question into the void.
3. Diff against a watermark (notice what changed). This is the part that separates a real intel system from a glorified RSS feed. Every competitor has a watermark — the last known state. New fetch gets compared to it. Pro $20 / Plus $100 / Max $200 today vs. the same yesterday → no change. A number moved → flag it.
4. Classify: material vs. noise (decide if it matters). A version bump with no behavior change is noise. A pricing cut, a license flip, a new product surface that overlaps ours, a funding round — material. The agent only escalates material. Everything else gets logged silently or dropped.
5. Write it down (the knowledge store). Material changes get appended to a canonical, dated, sourced log — plain markdown, version-controlled, the single source of truth the whole team reads. Durable findings get rolled up into a wiki so the knowledge compounds instead of scrolling away in a chat.
6. Route (tell someone). Threats are tier-ranked (A: same buying decision · B: big-lab adjacent · C: emerging/watch). Tier-A material pings a human immediately. Everything else batches into the next digest. The human opens their phone to “competitor X cut their team tier 60%” — not to fifteen “nothing changed” notifications.
That’s the entire job. The agent is the loop; the tools are how it touches the world.
The tools it chains
None of this is one magic model call. It’s a model orchestrating tools in a loop — which is the actual unlock:
- Web fetch → reads competitor pricing/changelog pages directly
- Search (cluster rotation) → cycles attention across competitor groups so each gets a scheduled deep-scan; discovers new entrants and funding before they hit your radar
- Platform APIs → HN search API, Reddit JSON, etc. for community signal
- A scheduler (cron / heartbeat) → makes it autonomous instead of something you have to remember to run
- A persistent knowledge store → markdown logs + a wiki, so today’s scan builds on every prior scan instead of starting from zero
- A task/alert channel → routes the 10% that’s material to a human, on the right urgency
Swap “competitive intelligence” for almost any monitoring role and the loop is the same. That’s why this is a category of job, not a one-off.
A real run
This isn’t a hypothetical. Here’s the agent’s actual log on one of ~15 tracked competitors. We mask the name as ***.ai (no need to name-and-shame), but the dates and the move are real:
2026-06-07: no change since baseline. direct overlap on BYO-key pricing. watermark holds. 2026-06-08: PRICING STRUCTURE CHANGE —
***.ai/pricing now shows a free individual plan; no $20/mo tier visible. re-verify next rotation. 2026-06-09: MATERIAL — CONFIRMED:***.ai’s $20/mo tier is gone. one less exact-price competitor at our entry tier.

Look at what’s happening there. Most days say “watermark holds” — the agent checked, nothing changed, it said so in one line and moved on. Then in the June 8 rotation it hit an anomaly a tired human skims right past: a competitor’s $20/mo tier wasn’t showing up anymore. It didn’t panic-escalate. It logged the flag, issued a re-verify directive, and ran the check again on the next rotation — and on June 9 it confirmed: the tier was silently gone. No announcement, no blog post, no press. It logged the implication (“one less exact-price competitor at our entry tier”) and surfaced it.
That flag → reserve judgment → confirm sequence is the watermark policy working as designed: rigorous enough not to cry wolf, patient enough to double-check, and tireless enough to catch a change nobody announced. A human analyst does that on their best day. The agent does it every day.

That’s the difference between a feed and an analyst. A feed shows you everything. An analyst shows you the one thing that matters. The agent is built to behave like the analyst.
And here’s the part that compounds: the loop isn’t a static script. Every run writes to a persistent memory and a wiki. The catches, the corrections, the watermarks it resets, all of it sticks. So the watch it runs this week is sharper than the one it ran a month ago, because it’s been writing down what it learned the entire time. It improves itself week over week instead of repeating the same checks forever.
Where it still needs a human
No overselling. Here’s what the agent does not do well, and what we keep a human for:
- Strategic read. The agent flags “a competitor’s cloud agents just went GA at $20.” Whether that reshapes our positioning is a human call.
- Judgment on ambiguity. “Is this a real competitor or just adjacent?” still gets a human review — misclassify it and the whole tier map drifts.
- The narrative. Turning fifteen dated log lines into “here’s the story of where the market is heading this quarter” is synthesis the human still leads.
The point was never fire the analyst. It’s delete the 80% that’s grind so the person does the 20% that’s actually worth $120k.
The receipt
Everything above is running right now — it’s the competitive watch behind the company that publishes this blog. The watchlist is real, the dated logs are real, the “$20 tier vanished” catch is pulled straight from it.
That’s the thing about building agents that do real work: the proof isn’t a demo, it’s the log. This post was written next to one.
If you want to see the machinery — the loop, the tools, the scheduling — it’s open source: github.com/5dive-ai/5dive. And if you’d rather just have the loop running for you, that’s what we do.
Next in the series: how to replace a market research analyst, an affiliate manager, and a community manager — each with the real loop and the real receipts.